To provide reliable redundant DNS service with DLZ, it is recommended that you setup at least two DNS servers, each with their own locally accessible copy of DNS data. When using DLZ in this manner, all the DNS servers are setup similarly, and they are all "master" DNS servers. There are no "slave" DNS servers because none of the servers perform zone transfers.
The problem then becomes how to reliably, safely, and quickly replicate DNS data to each of the DNS servers. Below we discuss a couple of options and the pros / cons of each one.
| Built-in homogenous (same) database server replication |
|
Many database servers provide built in (or easily added on) capabilities to perform data replication. The performance, reliability and procedure to setup database replication varies from one database to the next, so we won't cover that here. You should carefully review your database's documentation to see what capabilities it provides. If your database does provide replication, this may be the simpliest option to setup. The best way to setup DLZ for this option is to have a copy of your database server on each of the DNS servers (local database), and another copy of your database on a separate server. The database on the separate server is your "master" database and all data operations should take place on it. Updates to the master database are replicated automatically by your database system. While it is true that having both the DNS server and the replicated database on the same system will cause the DNS boxes to do more work, I feel this is the best option. It eliminates the possiblility of the DNS server's box being up and the replicated database server's box being down. It also eliminates to possiblity of a communication failure between the replicated database and the DNS server because of cable failures, etc.
The negatives of this option are that it may not provide the highest performance for your DNS server. Usually replication capabilities are provided by SQL or LDAP servers. These servers almost always communicate with their clients (in this case the DNS servers) through TCP/IP or Unix sockets. This communication has a cost and adds overhead to answering DNS queries. If you need the ultimate in performance, one of the other replication options may be able to provide better performance. If the performance of the DNS servers is adequate for your needs with this configuration, use it. |

| Heterogenous (different) database systems |
|
All the replication options below can be implemented using different database systems for the master database and the DNS server's databases. By using different database systems for the master database and the DNS server's databases, you can obtain the best performance for the DNS server's, while also taking advantage of the advanced capabilities of your master database. In these scenarios, I would recommend using an SQL database for the master database, and either the Berkeley DB or File System database on the DNS servers. The Berkeley DB and File System databases are much simpler and become part of the DNS server itself. Thus, they provide higher speed by reducing complexity and eliminating TCP/IP and Unix socket communication overhead. In order to implement heterogenous database replication, you will probably need to develop a simple program that will receive database updates from the master database server and properly update the local database. Keep in mind that while this program should be fairly simple in its business logic, it should be secure to prevent anyone other than authorized users / systems from making updates to your DNS data. |
| Simple manual database replication (cron on master database server) |
|
A program running on the master database server's box polls the master database for changes. If it finds any changes have occured, it will communicate those changes out to each of the other database servers. While this is not the best solution, it is acceptable and fairly simple to implement. This scales because only this one program polls the database instead of having each DNS server poll the database directly. It greatly reduces the waste of resources and bandwidth compared with running a similar program from the DNS servers. A more robust implementation would take advantage of the database's capabilities and use triggers to update a table within the database to indicate that data had changed and what data had changed. The polling program could then use the data in that table and wouldn't have to try to figure out what had changed. The polling program would also take advantage of the database to keep track of which updates it had sent to each of the other database servers. In this way, if one of the other database servers were down, it would not prevent all the servers which are up from being updated. Also, when a downed server was operational again, it would be informed of all the changes that occured since it went down and would be quickly brought in sync. |
| Advanced manual database replication (no cron) |
|
An advanced implementation of manual database replication would extend the robust implementation by allowing the trigger to signal an external program when changes had been made, thus eliminating the need for the external program to poll the database. The external program would then sleep until signaled again. If there were outstanding updates that could not be made, the program would sleep for a time out period, then try again without being signaled. This option is fairly robust and efficient. Its largest negative is the development effort that will be required to implement the sending program (the one running on the master database's box). Also, implementing a receiving program and security for it will take time. |
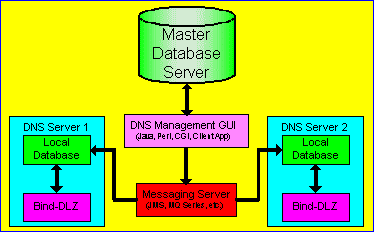
| Replication via Messaging server |
|
This option takes advantage of messaging servers to do a great deal of the work for you. By taking advantage of J2EE and implementing the receiving program as a message driven bean, even more work can be eliminated. Updates are made to the master database, and simultaneously an update message is sent to the messaging server. By using two phase commit, we guarantee the transaction either succeeds or fails on both the database and messaging server.
The message server's queue is configured for reliable broadcast (topic) messages. When configured this way, it is the message server's responsibility to guarantee that the update message is eventually received by the DNS server's database. Since the messaging server is configured for reliable broadcast, the message remains on the server even if the messaging server is brought down and back up. Of course, if the messaging server has a catastrophic issue, the message can be lost, and manual intervention by an administrator would be necessary. There are a few negatives with this approach, too. First, two phase commit is slower than only having to update one datasource (the database). Also, your GUI application is now dependent on having both the database and messaging server up. Lastly, by configuring the messaging server to support reliable broadcasts, it has more work to do in order to guarantee message persistence in case it goes down. |